- Introduction
- What is Iceberg
- Other advantages of Iceberg
- A challenging use case
- The plan
- The PoC
- TLDR - Key takeaways
Introduction
Apache Iceberg format is a great solution that enables a variety of interesting options for cost-effective data collection. The learning curve can be quite steep, but with the right knowledge and some starting tips can become a very interesting tool.
What is Iceberg
Apache Iceberg is an open source table format, designed to store large data tables. It is based on simple files that can be stored anywhere, and works well with data processing and analytics engines like Apache Spark, Hive, Trino and similar tools.
Iceberg tables are designed to be scalable, durable, and high-performing.
The format supports a variety of data formats, including JSON, CSV, and Parquet.
Tables can be partitioned, which allows for more efficient storage and retrieval of data using also parallel processing, if needed.
How it works and how data is stored
The basic concept on which Iceberg is based is dividing the dataset into smaller chunks, each of which is represented as a separate data file (the lower layer in the diagram below).
Each data file is assigned a unique ID, and each file can be linked by one or more manifest files, each one containing one row for each underlying data file, together with its metrics.
Groups of manifest files are then stored into manifest list files, each one containing references to multiple manifest files, together with stats and data file counts.
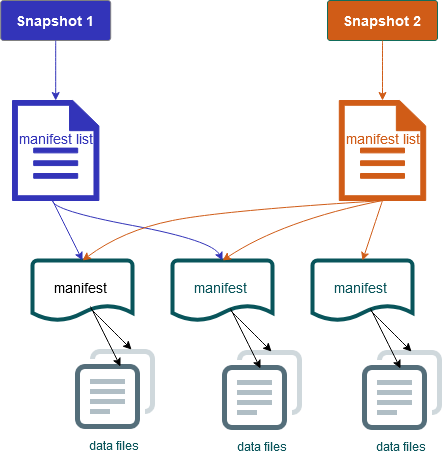
These layers of metadata are used like a sort of index to avoid reading manifests and data files that are not required for an operation. Both storage usage and retrieval times are reduced.
Let’s look at how it works with a couple of examples:
If a user wants to read a specific record in a dataset, they can specify the record’s ID and Iceberg will only read some metadata files and then retrieve only the data file that contains the record.
If a query needs to perform a count operation, or any other aggregation value like min, max, average and so on, it is likely that only metadata files will be read, avoiding an expensive full table-scan. This is because, if properly configured, the metadata layer itself stores statistics for each data column in each data file.
Other advantages of Iceberg
Apache Iceberg offers many advantages that makes it a great solution for data warehouses and data lakes.
Schema evolution
When the schema of the data is updated, these changes are just metadata changes, and existing data files don’t need to be rewritten to consolidate the update.
Hidden partitioning
Iceberg supports a variety of partitioning strategies, and tables can be partitioned on multiple columns. Partitioning offers the benefit of more efficient querying and updating of the data, because it can quickly locate the subset of data files that is relevant.
In addition to this, Iceberg handles hidden partitioning, meaning that the client doesn’t need to be aware of it, and can normally query the data, without explicitly reference partition-dedicated columns.
Also, if you need for any reason to change the partitioning, you can fix your table without having to plan an expensive migration, because the partition scheme can change over time, and Iceberg can handle this without ever touching the existing data.
Time travel
Iceberg stores data as a series of snapshots.
Each one is a point-in-time snapshot of the data, which can be used to restore the state of the data in that specific instant. This pattern makes possible time travel, which means that you can query the data at any point in time, not just the current content at query-time.
It’s up to you to decide how many snapshot you want to keep, configuring Iceberg according to your needs.
A challenging use case
 In the context of a web application for the monitoring of fleet of vehicles, we decided to try Apache Iceberg for a challenging use-case.
In the context of a web application for the monitoring of fleet of vehicles, we decided to try Apache Iceberg for a challenging use-case.
Size of data
Our need was to store about 1 million records every day, and to make them available for at least 10 years. Each record is a medium-length data structure that can vary from few to some kilobytes.
Near-real-time data feeding
The goal was also to make clients able to get their data on a per-day basis, but also to get data near-real-time, meaning new data being available just a few minutes after it is produced in the main platform.
Reading pattern
The data must be selectively accessed by the owner of the data, ideally through an API.
A remarkable point is that some clients are owners of tens of record per day, while other clients can have tens of thousands of records per day. And of course the response time must be always acceptable.
The plan
As often happens in the IT world, ideally cost and complexity should be kept as lower as possible, while at the same time, performance and scalability should unexplainably tend to infinite.
Our plan was to find a compromise for those requirements using Iceberg on S3 as a data store, and then exposing the data through an API with mandatory parameters to force the clients to trigger data queries that leverage the partitioning columns at every request.
To validate our plan, we started a POC that could then easily be converted in a production feature.
It was our first experience with Iceberg, so we needed to learn by doing.
Create a new Iceberg table
We created a new AWS Glue table on an S3 bucket, configured to use Apache Iceberg as Table Format, and Parquet for File Format.
We configured the partitioning on 2 data columns:
- the company that owns the entity
- the calendar day from the record timestamp
Feeding the table with data
We implemented a writing process this way:
- Data is produced in the platform, through many decoupled different pipelines
- A Flink job produces the aggregate that represents our final denormalized record
- Records are saved into the S3 Iceberg table defined in AWS Glue
The PoC
We built and deployed the artifacts, and at every data flush performed by Flink we started seeing new metadata files like these:
metadata/<version>-<UUID>.metadata.json
metadata/snap-<number>-<UUID>.metadata.json
metadata/<UUID>.metadata.json
and a lot of new new data files:
data/<randomstring>/companyId=123/timestamp_day=YYYY-MM-DD/<randomfilename>.parquet
Everything seemed to be working as expected.
The query pattern used by our clients, based on company and date, could leverage the partitioning and gave extraordinary good performance while being very cost-effective.
For example, launching a query with Athena we could get very good reading perfomance, and Athena scanned only an incredibly small amount of data, in proportion to the whole table size.
An expected problem
 We expected that this first release would have had a problem due to our feeding strategy. In fact, after a few days, while the table was growing, we started seeing a little degradation in performance.
We expected that this first release would have had a problem due to our feeding strategy. In fact, after a few days, while the table was growing, we started seeing a little degradation in performance.
Even if the size of the scanned data was still very low, the performance was getting worse.
Our writing process was configured to write the data on average every 5 minutes, and the partitioning was per day.
As a consequence we had a lot of small files, and a lot of metadata references to them.
After a few days feeding the table, the size of metadata had grown so much that it was about 90% of the data folder itself.
The analysis of the metadata became far more complex and costly, even if the number of real data files that were eventually read was very small.
The problem was that we were continuously adding data, and with this basic configuration, Iceberg was creating a new snapshot for each data insertion, and was retaining all of them.
In addition to that, the data files were very small and fragmented, because a new file was added at every insert transaction.
The easy (but just partial) solution
 We replaced the table with a new one, then we enabled the compaction managed function on the Glue table, confident that this would have had resolved the problem.
We replaced the table with a new one, then we enabled the compaction managed function on the Glue table, confident that this would have had resolved the problem.
After a few days we queried Athena about the size of the metadata, calling this query:
SELECT count(*) FROM "dbname"."tablename$manifests"
The number of manifests was actually smaller than before, and the performance was good and not giving any sign of degradation.
So far so good.
But then we made a double check launching from the AWS console a “Calculate total size” operation on the metadata and data folders.
Interestingly, the S3 folders were not smaller than before but were far bigger. The increase on metadata folder was a scary 500% in number of files, and 150% in size.
Of course we were missing something, and the cost of the S3 storage would have been unsustainable.
What we missed
 The problem was an oversight reading the documentation, because the managed compaction, by design, has just the responsibility to rewrite data files into a more optimized layout, based on their size and number.
The problem was an oversight reading the documentation, because the managed compaction, by design, has just the responsibility to rewrite data files into a more optimized layout, based on their size and number.
In other words, if inside a partition there is a high number of small files (the exact number and size depends on config parameters) the compaction job rewrites them as a single data file, simplifying also the metadata references to that chunk of data. This is the only intended meaning of “compacted”.
What we missed was that compacting the data doesn’t imply that the orphan files are also deleted. This behavior is exactly as happens with some RDBMS, where deleting records doesn’t mean that you are actually freeing disk space.
So, even if the metadata complexity was lower, the performance was good, and the compaction process was effectively optimizing the data reducing its fragmentation, the system was leaving behind on S3 a huge quantity of junk files.
The final solution
We ended up creating a Lambda function that continuously executes a VACUUM command leveraging Athena, so that all expired snapshots and all orphan files (both data and metadata) are physically removed from S3.
Here is a comparison of some key metrics collected while using the three different configurations described above:
| Metric | Just write | +Compaction | +Compaction +Vacuum |
|---|---|---|---|
| Number of snapshots | ~320/day | 10 | 10 |
| Number of metadata files per day | 2,200 | 10,500 | 67 |
| Size of metadata files per day | 5,200 MB | 7,900 MB | 100 MB |
| Number of data files per day | ~300K | ~800K | 50K |
| Size of data files per day | 5,600 MB | 8,500 MB | 900 MB |
| Number of files referenced per day (excluding orphan files) | 300K | 50K | 50K |
The improvement and the savings in terms of disk usage is clear.
The downside is that compaction and vacuum operations performs a lot of API calls on S3, so it is necessary to tune the parameters in order to find a good balance that works for each use case, balancing cost of storage, cost of API calls, optimal file size for Iceberg to work good with your access pattern.
TLDR - Key takeaways
The road to mastering Apache Iceberg is long and hard for newbies, but it’s definitely a game-changer technology.
Writing big batches of data is far easier than adding it little by little. If you have to do so, consider that you’ll have to master the compaction and the vacuum processes.