- Context
- The cross-checking need
- Performance and cost considerations
- Rollup jobs
- Transform job
- Advantages and disadvantages
- Some quick calculations
- Final considerations
Context
This story is about an IoT project, hosted on AWS, ingesting data produced by some devices.
The system is a distributed architecture, where after the ingestion stage, the raw data pass through an Amazon Kinesis Data Stream.
This stream is the source for a bunch of services, each one responsible for different processing that we need to perform on the data.
Kinesis is a key point for the system, because it allows each consumer to read events and process them at its speed, making each processing pipeline independent from the others. Kinesis can also absorb all traffic peaks and allows the ingestion to continue when one or more processing pipelines are temporarily disabled, for any reason.
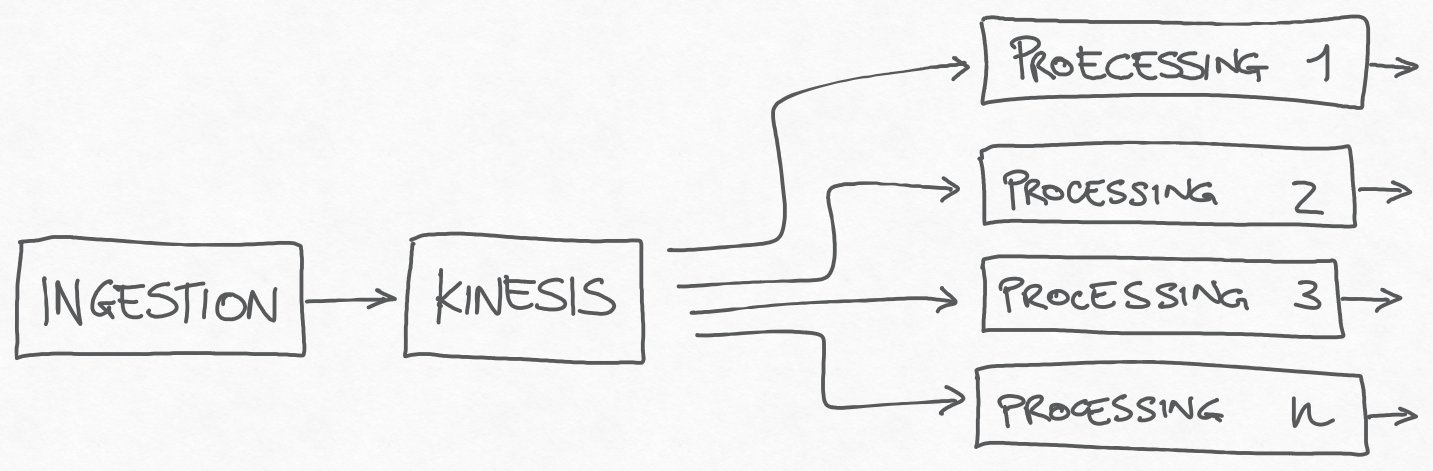
Kinesis Data Stream is the source of all processing pipelines
The cross-checking need
During the project’s evolution, it became important to validate the processings performed on the data stream. The idea was to find a way to save somewhere the raw data, so that it could become possible to cross-check the result, make quick troubleshooting, and validate the processing.
When the quantity of data is huge you cannot simply save it on a relational database and query it in all possible ways, present and future. But OpenSearch (and ElasticSearch too, of course) can do it pretty well, and is also a great tool to query and filter data, make advanced aggregations, and visualize the results, literally in seconds, without the need for preliminary data preparation.
So we added a sort of a sniffer component, that started to consume events from Kinesis and to save them into OpenSearch, after a quick enrichment/denormalization process.
The result was an index with all the data from all devices, and OpenSearch has proven to be a great tool for our troubleshooting needs.
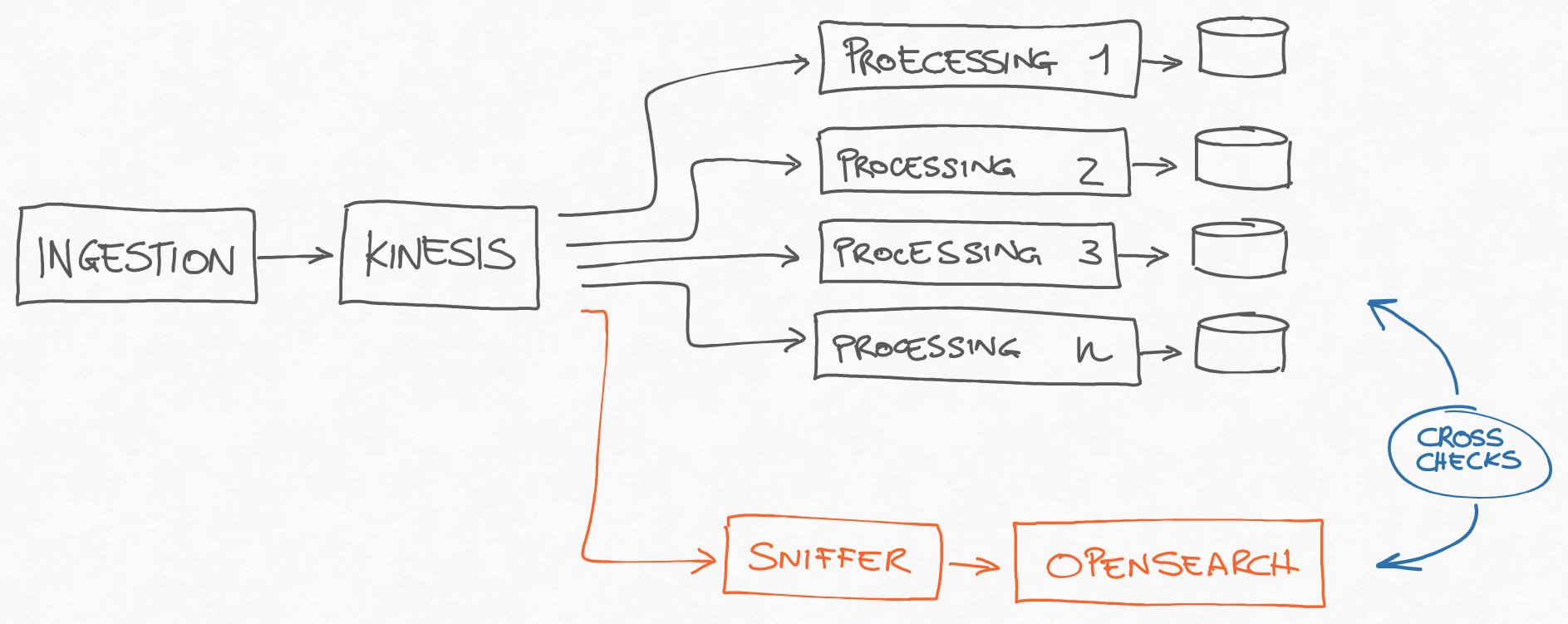
Data “sniffing” for cross-checking the processed data
Performance and cost considerations
OpenSearch is very good with big quantities of data, but in our scenario each document is about 2KB and we have to store 40 million documents every day.
We started using daily indexes. From a performance perspective, OpenSearch worked very well, but each index was about 22 Gigabytes, which means something like 8 Terabytes per year of data. A bit too much for a service that after all is not strictly part of the system, but is something like a “data observability tool”.
The cost started soon to be too high, and the first option that we saw was to delete old data and keep just the tail, for example, the last two or three months.
It was for sure an option, but sometimes it could have been interesting to execute queries on long-term data, for example just the data from a single device, but over a long period of time, for example one year, or even more.
A better alternative was finding a way to aggregate the data, reduce the data size and so keep more data by paying a similar cost.
Rollup jobs
The cleaner way seemed to be using Index rollups, a feature that automatically reduces data granularity by making metric aggregations, in a completely transparent way.
After some tests, we noticed that with our data we had some errors. Probably it was related to some problem in our data, or may be there was a bug because OpenSearch was relatively young. We didn’t discover the reason behind those failures, we had no useful logs and no time to spend on that investigation.
In addition to that, this solution is limited in the types of aggregations, because rollups jobs can perform only All, Min, Max, Sum, Avg, and Value Count.
In our scenario it could be useful to us more freedom in the aggregation logic, for example, collecting the distribution of a metric.
So we explored the option of using index transform, and through this feature we finally reached our goal.
Transform job
The solution is based on the idea of having 2 different sets of data, for different needs:
- A sliding window of uncompressed raw data
(in our case configured to be the last 2 months) - A historical set of compressed data, going into the past as long as possible
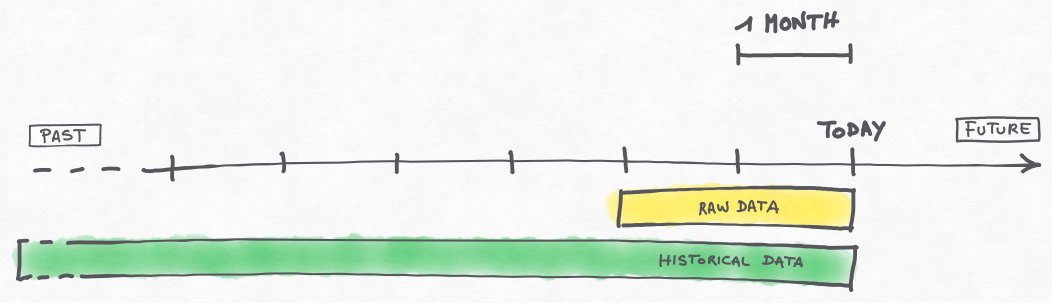
The timeline with the two datasets
Shortly, this is how the solution works:
- An EventBridge rule is scheduled to be executed every day and start a Lambda function
- The lambda creates a monthly index and its mapping for the compressed data (in OpenSearch these operations are idempotent)
- The lambda deletes the daily indexes of uncompressed data older than the configured sliding window (in our case this means that is deleted the 61st daily index before execution time)
- The lambda creates the daily transform job, for immediate execution
- The transform job is executed, and works on the data of the previous day
- The data is aggregated in blocks of 1 hour, per single device
- Some metrics are aggregated using the available standard aggregations (min, max, average and so on)
- Other metrics are processed using custom scripted_metric aggregations, and leveraging the flexibility of map/combine/reduce scripting, in our case the data is reduced into custom distribution reports
Advantages and disadvantages
According to the investigation we need to take, we can decide whether it is better to use the most recent raw data as-is, or the historical compressed data.
If, for example, the need is to check what exactly a specific device has sent the last week we can use the daily indexes of the uncompressed raw data.
Instead, if the need is for example to study a trend during the last year, the compressed monthly indexes are the right data source.
A negative aspect of this solution is that when we start working on a visualization we have to decide in advance on which of the two data sources we want to work. The schema is different so a visualization created on the daily index will not work on the monthly indexes and vice-versa.
It’s not really a major problem, because usually you know well what source fits well on the specific need. Anyway, the index rollup feature is for sure better from this point of view, because the index is the same and you don’t have to handle this double data source.
Some quick calculations
Daily raw-data uncompressed indexes
- Each JSON document is about 1.6 KB
- Each index contains on average 40 million documents
- The daily index size is on average 23 GB
- One month of data is about 700 GB
Monthly aggregated indexes
- Each JSON document is about 2.2 KB
- Each index contains on average 15 million documents
- The index monthly size is on average 6 GB
Final considerations
It’s easy to see that the resulting compression ratio is roughly 100:1.
This means that, even configuring historical indexes for 1 replica and so doubling their size, the disk space needed to handle one month of raw data allows us to store more than 4 years of aggregated data.
In addition to that OpenSearch is much faster querying the aggregated indexes.
Before implementing this solution we had stored 1 year of raw data, but due to performance troubles, we had to scale out the OpenSearch cluster up to 6 nodes. This generated a considerable cost, both for computing and storage resources.
With this serverless solution that automates the data aggregation, we were able to reduce the cluster size to just 3 nodes, each one with smaller storage.
In other words, with a small and acceptable loss of data, today we spend less money while we can afford to retain all historical data.